Project Category: Mechanical
Join our presentation
About our project
The ability to control complex fluid flows has important practical applications in industry. Active Flow Control (AFC) is a promising solution – i.e., controlling the flow through dynamically actuating it using sensory feedback. It has the potential to revolutionize technology in several applications including drag reduction in transportation systems, mixing enhancement in chemical processing, pipelines, production, bioengineering, and jet noise control in aviation. In real-world fluid systems, the flow is typically highly turbulent and complex, making their dynamics high-dimensional and chaotic. The inherent stochasticity in turbulence renders AFC a challenge using conventional control methods. Rising energy demands warrant an accelerated campaign to advance AFC technology. The Fluid Pinball is a toolkit that is used to advance the state-of-the-art in AFC. By design, it is a diagnostic configuration that can emulate flow instabilities that are typically observed in the industry. It consists of three cylinders placed in a moving fluid. The wake behind this cylinder cluster is chaotic, and the unsteady vortices (swirling flow structures) that are shed from the cylinder faces induce drag and fluctuating forces on the cylinders, which can lead to resonant excitation, and undesired cylinder vibration. Three remote air-speed sensors (hot-wire probes measuring velocity magnitude) are placed in the wake of the pinball to detect the downstream effects; note the stochastic sensor signals in the animation below of the uncontrolled flow.
The objective of this project is to design controllers to minimize fluctuating forces on the cylinders using the sensor information alone. The flow is simulated using Computational Fluid Dynamics on the University of Calgary’s Advanced Research Computing cluster. The controller relays information to motors (actuators) mounted on the cylinders to rotate them in order to suppress the wake fluctuations. To minimize the power consumed by the motors to rotate the cylinders, the controller additionally tries to find more practical solutions that have low cylinder rotation rates. Leveraging their well-known capabilities at solving complex tasks, we use machine learning techniques to solve this problem – (1) Genetic Algorithms based on natural selection, and (2) Reinforcement Learning based on reward-based learning using neural networks.
The controllers are allowed to search a large, 12-dimensional parameter space for possible actuation strategies – all motors can rotate with oscillatory motion (sinuous actuation) or uniform motion (constant rotation) with rotation speeds up to 10,000 RPM. A standard strategy to find an optimal control solution would be to search the entire parameter space by performing a grid search, which would take several hundred thousand hours. For a search task that would have likely taken several months (even years) to conduct, our ML-based controllers were able to find near-optimal control solutions within 5 minutes. Shown below is an example of a control solution found by our GA.
Meet our team members
Manmeet Dhiman
I am a final year mechanical engineering student with interests in biomedical engineering, machine learning, and software development. I have worked as a reliability engineering intern at CNRL Albian Sands where I gained experiences in field operations, equipment monitoring, and data analysis. I am responsible for the Reinforcement Learning based controller in this project. In my free time, I enjoy playing basketball, hiking, staying active, and programming.


Kevin Manohar
I am a final year mechanical engineering student with interests in aerodynamics and machine learning. I worked as a nuclear thermal-hydraulics intern at the Paul Scherrer Institute in Switzerland where I gained experience in laser-based flow diagnostics and data-driven algorithms. For this project, I am responsible for the cost function design, post-processing of CFD simulations, and data analysis. In my free time, I enjoy trail running, backpacking, and playing the piano.
Joel George
I am in my final year of Mechanical Engineering, and interned at Garmin Ltd. My interest in this project is rooted in my interest for control theory, and recent interest in machine learning. I am responsible for the Genetic Algorithm based controller in this project. In my free time, I enjoy outdoor-activities such as hiking and mountain biking.


Richard Gao
I am a final year mechanical engineering student with interests in aerospace R&D and computational science. During my internship at ABB Switzerland, I was responsible for CFD simulations of high-voltage circuit breakers and developing data analysis scripts. For this capstone project, I am responsible for developing the automation architecture and running the CFD simulations. In my free time, I enjoy programming and plane spotting.
Akshat Yugin
I am currently completing my fourth year of Mechanical engineering after completing an internship. During my internship, I got exposed to pipeline operations, hydraulics, modelling, data analysis and very much enjoyed the technical work. What intrigued me about this capstone project was its novel approach to solving a complex problem, and it was a great opportunity to get exposed to the field of machine learning. I am responsible for the Reinforcement Learning based controller in this project.

Details about our design
HOW OUR DESIGN ADDRESSES PRACTICAL ISSUES
The ability to control complex fluid flows has important practical utility in industrial applications. The 20% of global energy expenditure that is attributed to increased fuel consumption in transportation [1] mainly arises due to aerodynamic phenomena such as induced drag caused by separated flow. Such phenomena can be mitigated by closed-loop flow control strategies – i.e., controlling the flow through actuators using sensory feedback. These controllers can be used to delay laminar-turbulent transition, control separation location or control large-scale instabilities (such as vortex shedding) through dynamically actuating the flow in response to its state. Other applications include jet noise control in aviation, enhanced mixing in chemical reactors, industrial production, combustion and medical devices [1]. However, the design of such a controller is challenged by the high-dimensional, multi-scale and non-linear chaotic dynamics that typically govern turbulent flows in industrially relevant conditions. In particular, it is desired to have a robust controller that is effective in a large variety of flow regimes and one that is quick enough to respond to fast changes in the flow.
For instance, say that the drag on an aircraft is to be actively controlled by means of synthetic jets. The aircraft undergoes drastically different flow regimes throughout its flight envelope – from takeoff to landing. The control input, say the oncoming air speed measured by the aircraft, frequently changes due to the highly non-linear interactions between the oncoming turbulence and the aircraft body. Thus, the design of a robust feedback controller is warranted to mitigate drag-inducing separated flow throughout the flight path.
Machine Learning (ML) techniques have been recently used to exploit large amounts of simulation and experimental data to address the above-mentioned control challenges; with promising success [2]. Our study will provide valuable insights regarding the expectations and limitations of such methods for use in practical problems.
[1] S. L. Brunton and B. R. Noack, “Closed-loop turbulence control: Progress and challenges,” Applied Mechanics Reviews, vol. 67, no. 5, 2015.
[2] S. L. Brunton, B. R. Noack, and P. Koumoutsakos, “Machine learning for fluid mechanics,” Annual Review of Fluid Mechanics, vol. 52, pp. 477–508, 2020.
WHAT MAKES OUR DESIGN INNOVATIVE
While the field of machine learning (ML) based active flow control (AFC) is in its infancy, numerous experimental studies have been performed to evaluate various architectures on their own. However, a comparative study into the design of different ML-based controllers is lacking in the literature. In this project, we perform a comparative analysis of Genetic Algorithm (GA) and Reinforcement Learning (RL). Another unique aspect of the study is its application of the RL based architecture to the complex dynamics of the fluid pinball with a minimal number of velocity sensors. In literature, RL has only been applied to synthetic jet based control to single cylinder wake-dynamics with a higher number of sensors in the laminar flow field [1]. This aspect of the study alongside the testing of the controller on turbulent and perturbed turbulent inlet flows makes the control challenge substantially more difficult for the controller. Lastly, the use of ML for AFC is primarily motivated by its ability to discover new, un-intuitive solutions to the control problem. This aspect is especially important when the control objective requires a balance between performance and controller effort for such a system.
[1] J. Rabault, H. Tang, A. Kuhnle, Y. Wang, and T. Wang, “Robust active flow control over a range of Reynolds numbers using an artificial neural network trained through deep reinforcement learning,” Physics of Fluids, vol. 32, no. 5, 2020.
WHAT MAKES OUR DESIGN SOLUTION EFFECTIVE
While the extent to which they fulfill the control objective varies, both the genetic algorithm (GA) and reinforcement learning (RL) based controllers are effective at improving from their initial state. However, the fundamental approach that each architecture uses makes them more effective at different aspects of the control problem.
The GA based controller is at its core an optimizer. It evolves a solution set based on the full state of the system; in this case, the full sampling period of the fluid pinball per individual. Due to the solution set being relative to the previous set, the GA relies heavily on each solution of the set experiencing relatively similar input conditions. That is, all individuals in a population are evaluated based on the state generated by the same input condition. This process is effective as it optimizes the solution set quickly to meet the control objectives with a small amount of input data. However, the solution set is often specialized to the input condition of the system. That is, the near-optimal solution found may not be robust for marginally different input conditions.
The RL based controller on the other hand has a higher resolution control of the system. This architecture tries to find the best sequence of actions to take for a given flow state. Therefore, this approach can respond appropriately to changing flow state conditions. As it learns in its exploration phase, it starts to produce more effective actuations for any state input. This aspect of the controller makes the RL control strategy more robust to changes in the input conditions of the system. However, in contrast to the GA, the RL architecture requires significantly more training data, and thus takes longer to converge to a solution.
HOW WE VALIDATED OUR DESIGN SOLUTION
To validate our ML architectures, we test and evaluate the finalized architectures on the Fluid Pinball. Due to COVID-19, we are modelling the Fluid Pinball numerically using Computational Fluid Dynamics (CFD) instead of using an experimental setup. We are using two separate cost functions to represent our two control objectives – reducing the velocity variance in the three sensors at steady state while keeping the motor power consumption low. These two cost functions are combined to a single objective total cost function, and the objective of ML architectures is to reduce this single objective cost function.
Our validation has three aspects:
- Robustness in different flow regimes
- Performance of the architectures in their learning phase
- Performance of the architectures at steady state (post learning)
Robustness Assessment
To test if the ML architectures are robust in different fluid environments, their performance is tested in the turbulent flow regime with two different types of inlet flow – constant and varying inlet flow. This is shown below.


Learning Phase Assessment
In order to acquire a good control strategy, the ML architectures have to collect data about different actuation or actuation sequences in the Fluid Pinball. As this is being done, the ML architectures start to recognize and “learn” good control strategies. To save CFD simulation time, the length and amount of actuations done in the learning phase are limited i.e. not to steady state. The objective of the learning phase is to validate the ML architectures produce improved cost with respect to their initialization. The performance is presented in the table below for the reduction in the total cost function which captures both our control objectives.

Both architectures are able to learn with respect to their initialization for both types of inlet flow.
Steady State Assessment
Once the ML architectures learn a good control strategy, the architectures are put to the test in a longer steady state run. The objective of the steady state assessment is to validate that the ML architectures can meet our project objectives in a steady state setting. The performance is presented in the table below for the reduction in velocity variance of the three sensors compared to the unactuated flow.

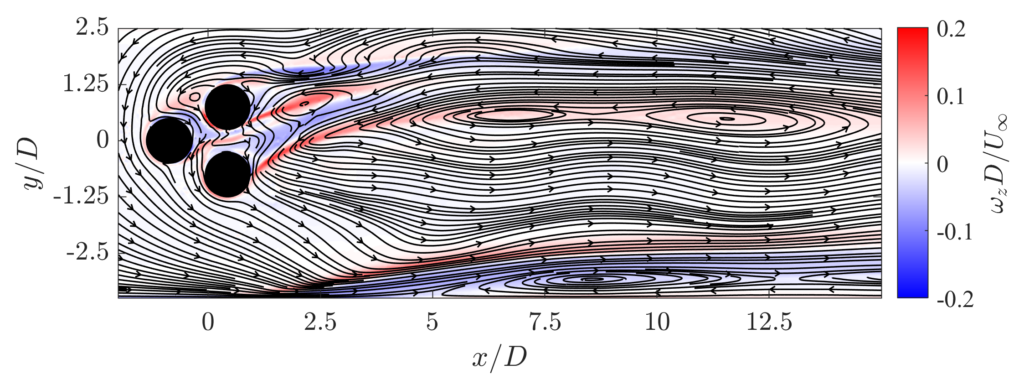
GA performs well in both scenarios above. Further testing is required to establish RL’s robustness to both types of inlet flows. The snapshots below provide a comparison of the unactuated flow state to the controlled flow state. The snapshots highlight the vorticity in the flow field which are related to the velocity fluctuations and need to be suppressed!


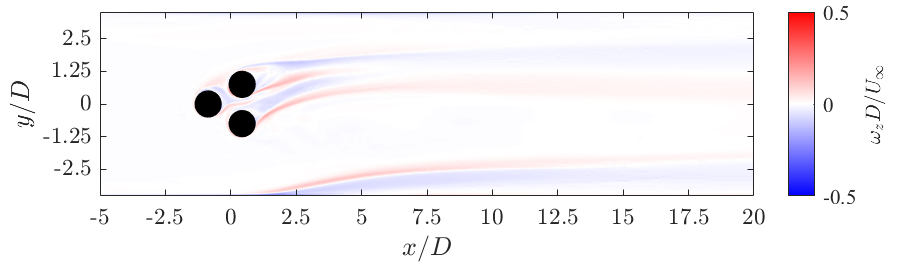
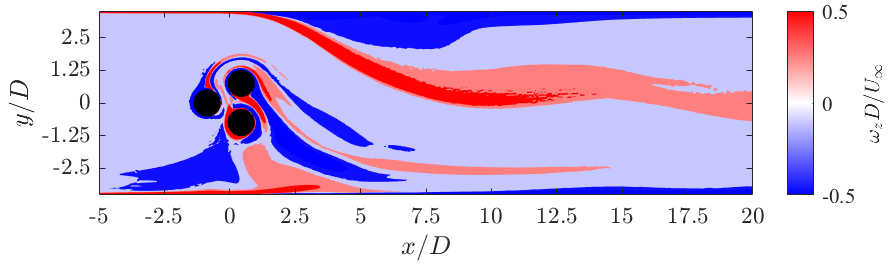

FEASIBILITY OF OUR DESIGN SOLUTION
Since our project is numerical instead of experimental, the feasibility of our design solutions depends mainly on the computational time required by our Computational Fluid Dynamics (CFD) simulations and consequently the available computational resources. Using the University of Calgary’s Advanced Research Computing (ARC) cluster to run our CFD simulations, our current design solutions require one week to achieve convergence for the Genetic Algorithm (GA) and two weeks for Reinforcement Learning (RL). The feasibility is therefore subjective, as the convergence time will decrease with more computational resources. Overall, we consider our design to be a reasonable approach; a solution that produces robust results while not requiring months of simulation time.
If our project was experimental, it becomes much easier to implement our GA and RL controllers (neglecting issues such as noisy data, natural mechanical stiffness of the rotating system etc.), and to achieve a converged solution. The one week of CFD simulations required by the GA equates to approximately 300 seconds or 5 minutes of real time data. Therefore, it would only take 5 minutes for the GA to reach a converged solution in an experimental setup. Likewise, the RL would only require 7 minutes. Furthermore, we avoid the possibility of unavailable computational resources. This reduction in convergence time allows us to explore a larger space of control strategies, potentially finding an even more effective design solution than our current ones.
Our designs demonstrate robustness to perturbations in the system input, and are able to search a large parameter space to find near-optimal control solutions to a chaotic system in a matter of minutes. While the exact method of actuation is entirely application-dependent, our project has demonstrated that ML-based controller designs are highly promising to advance AFC technology.
Partners and mentors
We would like to thank the following people for their assistance in this project.
We thank Dr. Robert Martinuzzi for facilitating this challenging yet rewarding project. His guidance on fluid mechanics, and machine learning tools has made this project an excellent learning opportunity. Additionally, his assistance in retrieving existing work related to the project played a significant role in its progression.
We thank Peng Zhong for providing us with the Computational Fluid Dynamics (CFD) model, and his guidance on the CFD setup. Additionally, his graduate thesis provided valuable insights into the fluid pinball experimental setup.
We thank the University of Calgary for providing remote access to the Advanced Research Computing (ARC) cluster for performing CFD simulations.
We thank A.J. Ebufegha for providing guidance on mechanisms used in the genetic algorithm.
We thank Dr. Philip Egberts for providing valuable feedback on information presented during the proposal and progress review meetings.
We thank Dr. Simon Li for providing resources related to the course deliverables.
Our photo gallery